
Rynek RAG (Retrieval-Augmented Generation) rośnie z 1,2 mld USD w 2024 do prognozowanych 11 mld USD w 2030 - 49% rocznie. Według McKinsey 71% organizacji używa już generatywnej AI w co najmniej jednej funkcji biznesowej. Deloitte potwierdza, że 42% z nich widzi realne oszczędności i wzrost produktywności.
Jednocześnie 8 na 10 projektów wdrożenia asystenta AI w polskich firmach MŚP zaczyna się od jednego zdania: „chcemy zrobić coś jak ChatGPT, ale na naszych dokumentach”. I trzy miesiące później - kończy tym samym zdaniem, bez żadnej działającej aplikacji.
Ten wpis jest playbookiem, który ma to zmienić. Nie wstępem do RAG (tego w internecie jest dość). Nie listą best practices. Konkretnym, 4-tygodniowym harmonogramem, który robimy u klientów - z nazwami narzędzi, metrykami sukcesu i decyzjami, które trzeba podjąć po drodze.
Przed lekturą zrób sobie herbatę. 12 minut czytania. Na koniec masz template do pobrania.
Spis treści
- Dlaczego 4 tygodnie, a nie 3 miesiące
- Tydzień 1: Audyt i czyszczenie źródeł
- Tydzień 2: Embedding i hybrid retrieval
- Tydzień 3: Grounding prompt i eval set
- Tydzień 4: Pilot na jednym dziale
- Co dalej: tydzień 5 i kolejne
- Pobierz template i checklist
Dlaczego 4 tygodnie, a nie 3 miesiące?
Większość projektów RAG w polskich firmach pada na jednym z trzech etapów:
Paraliż decyzyjny na starcie. „Musimy najpierw przemyśleć architekturę, zrobić RFI na dostawców, wybrać model, opracować strategię AI.” Po trzech miesiącach obradowań nic nie działa, a zespół traci wiarę, że kiedykolwiek zacznie działać.
Zachłystnięcie się skalą. „Wrzućmy do bazy wszystkie dokumenty firmy i zobaczmy, co się stanie.” Po tygodniu system odpowiada na pytania z dokumentacji sprzed 5 lat, myli regulaminy różnych działów i halucynuje procedury, których nie ma.
Brak definicji sukcesu. „Zobaczmy, czy to w ogóle działa.” Po miesiącu użytkownicy mówią „czasem dobrze, czasem nie”, zespół IT nie wie, czy to jest już produkcja czy jeszcze eksperyment, a zarząd nie wie, czy dalej inwestować.
Playbook, który opisuję, rozwiązuje wszystkie trzy. Ogranicza zakres (pilot, nie big bang), wymusza mierzalność (3 metryki od pierwszego dnia) i dzieli pracę na cztery tygodnie, w których każdy ma jasny cel.
Nie obiecuję, że w 4 tygodnie masz wdrożony RAG dla całej firmy. Obiecuję, że masz działający pilot dla jednego działu, który zmierzyłeś - i masz dane do decyzji, czy i jak rozszerzać.
Tydzień 1: Audyt i czyszczenie źródeł
Najdroższa lekcja w projektach RAG: jakość odpowiedzi asystenta w 70% zależy od jakości źródeł, nie od jakości modelu. Możesz mieć Claude Opus, najlepszy embedding i najnowocześniejszy reranking - jeśli dokumenty są śmieciem, dostaniesz inteligentnie brzmiący śmieć.
Dlatego pierwszy tydzień to nie jest tydzień wdrożeniowy. To tydzień porządkowania.
Krok 1.1 - Source registry
Zrób listę każdego źródła wiedzy w firmie, które rozważacie dodać do asystenta. Konkretnie:
- SharePoint (które biblioteki, które foldery)
- Google Drive (które Shared Drives, które foldery prywatne)
- Confluence (które przestrzenie)
- Baza ticketów (Zendesk, Intercom, Freshdesk, HubSpot)
- Lokalne dyski z dokumentami archiwalnymi
- Email archives (jeśli planujecie je włączyć - pomyśl dwa razy)
- Pliki PDF-y i Word-y przesyłane załącznikami
- Wewnętrzne wiki, Notion, Obsidian
Dla każdego źródła zanotuj: właściciel, data ostatniej aktualizacji, liczba dokumentów, typ treści (procedury, umowy, wiedza techniczna, FAQ).
Już na tym etapie odsiejesz 30-40% źródeł jako „nieaktualne” albo „duplikaty”. To dobra wiadomość. Nieaktualny dokument w asystencie jest gorszy niż nieistniejący.
Krok 1.2 - Chunking z zachowaniem struktury
Gdy masz już zestaw źródeł, trzeba je podzielić na kawałki (chunks) - bo model AI nie przetwarza całych dokumentów, tylko fragmenty, które dostaje jako kontekst.
Rekomendacja z produkcji: 200-600 tokenów na chunk, z zachowaniem nagłówków. Czyli jeśli dokument ma sekcję „Procedura reklamacji” z podpunktami 1.1, 1.2, 1.3 - chunki dzielimy po podpunktach, ale każdy chunk zawiera ścieżkę nadrzędnego nagłówka.
Efekt: model widzi nie tylko treść fragmentu, ale też gdzie w dokumencie się znajduje. To radykalnie zmienia jakość odpowiedzi. Fragment „zwrot przysługuje w ciągu 14 dni” sam w sobie jest niejednoznaczny - ale w kontekście „Procedura reklamacji > Zamówienia zagraniczne > Warunki” staje się precyzyjny.
Krok 1.3 - Metadane
Każdy chunk dostaje metadane techniczne, które potem używamy do filtrowania i routingu:
- owner - właściciel dokumentu (do kontaktu przy niejasnościach)
- produkt/dział - którego obszaru dotyczy (dla asystentów dedykowanych)
- region - jeśli firma działa na różnych rynkach
- data ważności - kiedy treść była ostatnio aktualizowana
- security label - kto może widzieć ten fragment (public / internal / confidential / restricted)
Metadane służą dwóm rzeczom. Technicznie - pozwalają filtrować wyszukiwanie tak, żeby asystent działu HR nie zwracał fragmentów ze strategii sprzedażowej. Operacyjnie - dają audytowalność: wiesz, kto odpowiada za konkretny kawałek wiedzy i kiedy był aktualizowany.
Krok 1.4 - Redakcja PII i podstawa prawna
Zanim cokolwiek zaindexujesz - przejrzyj dane pod kątem PII (danych osobowych). Nazwiska klientów w mailach, numery dowodów w umowach, dane zdrowotne w dokumentacji HR.
Dla każdej kategorii danych osobowych odpowiedz na pytanie: „mamy podstawę prawną, żeby te dane przetwarzać przez system AI?” Zgodnie z RODO i EU AI Act samo przeniesienie danych z SharePointa do bazy wektorowej jest nowym przetwarzaniem, które wymaga osobnej podstawy prawnej.
W wielu przypadkach odpowiedź brzmi: „nie”. Wtedy: redakcja (automatyczna lub ręczna) przed indeksowaniem. Nie wrzucamy śmieci do asystenta; nie wrzucamy też danych, których nie wolno nam używać.
Ten krok oszczędzi Ci tygodni dyskusji z prawnikiem i DPO później. Jeśli dopiero mapujesz, gdzie w ogóle lądują Twoje dane AI, zacznij od wpisu filarowego 4 poziomy suwerenności AI - który pasuje do polskiego MŚP - on daje ramę do klasyfikacji danych, której będziesz potrzebował tutaj.
Tydzień 2: Embedding i hybrid retrieval
Mamy czyste źródła. Teraz trzeba je tak zindeksować, żeby asystent znajdował właściwe fragmenty, gdy użytkownik pyta.
Krok 2.1 - Stack wyszukiwania
Konkretnie u nas w Ragenie używamy stacku:
- wektorowa baza danych do przechowywania embeddingów. Szybka, open-source, dobrze się skaluje.
- model do embeddingów - model generujący embeddingi dla polskiego i innych języków.
- BM25 - klasyczny algorytm wyszukiwania słów kluczowych. Brzmi staro, ale w 2026 nadal może być jest niezbędny.
- model do rerankingu - model, który bierze top 20-50 wyników z hybrid search i przestawia je według faktycznej relevance.
Schematycznie pipeline wygląda tak:
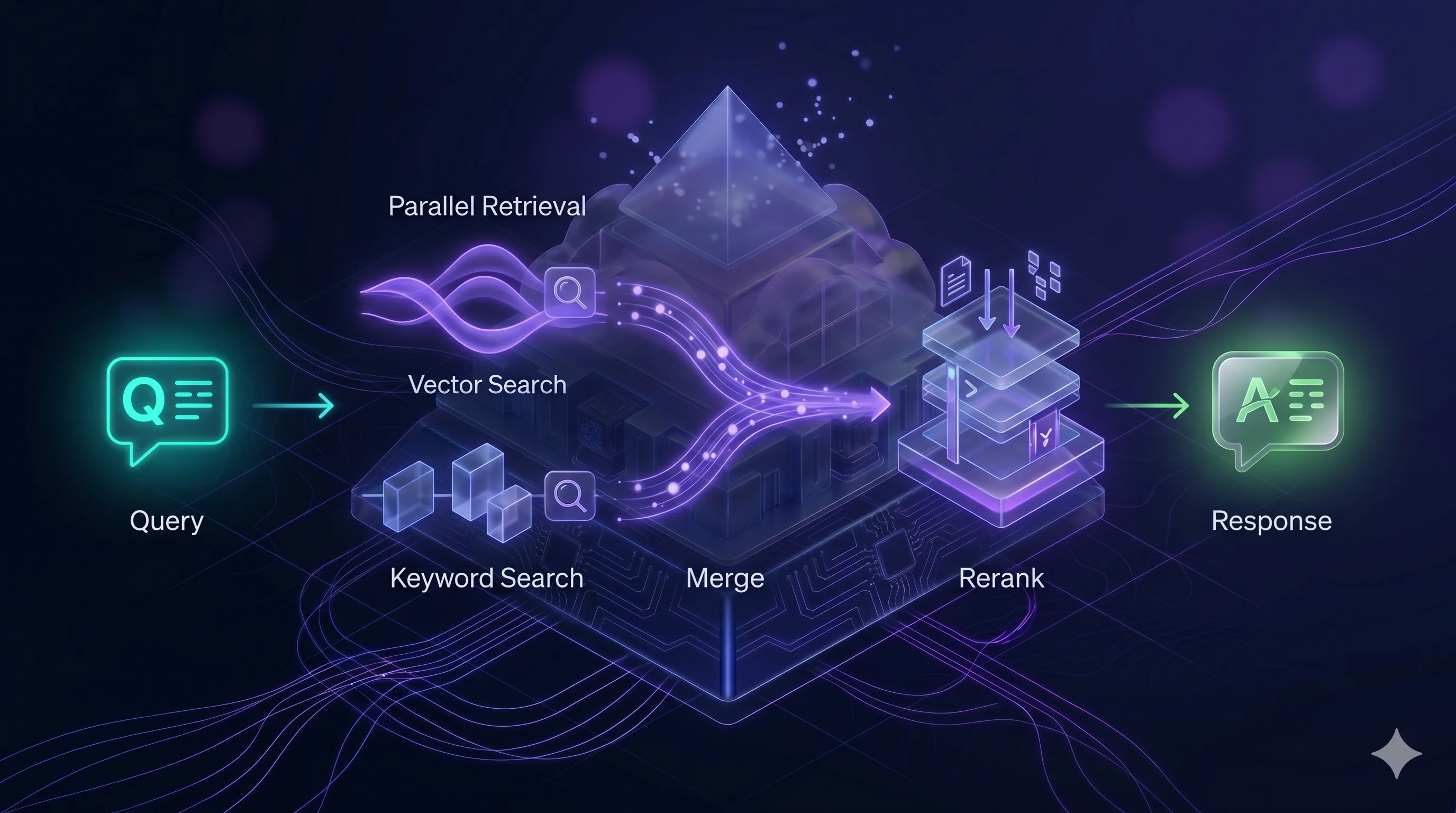
Możesz użyć różnych komponentów (Pinecone, Qdrant, OpenAI embeddings, Cohere). Ale ten konkretny układ czterech warstw jest krytyczny. O tym niżej.
Krok 2.2 - Dlaczego hybrid retrieval, a nie tylko wektory
Najczęstszy błąd w pierwszych wdrożeniach RAG: „wrzucimy wszystko do bazy wektorowej i niech semantyczne wyszukiwanie zrobi robotę”. Nie zrobi.
Wyszukiwanie wektorowe jest świetne dla pytań o znaczenie („jak rozwiązać problem X” → znajduje procedurę naprawczą, nawet jeśli słów się nie pokrywa). Ale jest słabe dla pytań o konkret („jaki jest status zamówienia FV-2024-0031” → chcesz dokładnie ten numer, a nie „coś podobnego”).
BM25 jest dokładnie odwrotny. Świetny dla dokładnych dopasowań słów kluczowych, słaby dla pytań koncepcyjnych.
Hybrid retrieval łączy oba mechanizmy. Query idzie równolegle do obu silników, wyniki są łączone, i najlepsze trafiają do kolejnego kroku. Polski użytkownik pisze „jak zrezygnować z subskrypcji”, a dokument używa frazy „rozwiązanie umowy o świadczenie usług” - wektory to wyłapią. Potem pyta „co z fakturą 2024/456” - BM25 znajdzie dokładnie tę fakturę.
Dopiero oba razem dają jakość, która nadaje się do produkcji.
Krok 2.3 - Reranking to nie opcja, to wymóg
Hybrid retrieval zwraca 20-50 kandydujących fragmentów. Z tej listy tylko 3-5 trafia ostatecznie do kontekstu modelu (bo kontekst jest ograniczony, a dłuższy kontekst = wolniejsza i droższa odpowiedź).
Problem: pierwsze 20 wyników z wyszukiwania nie jest uporządkowane od najlepszego. Bazy wektorowe i BM25 używają różnych metryk. Top-1 z wektorów może być gorszy niż top-5 z BM25.
Reranker to osobny model, który patrzy na pytanie użytkownika i każdego z 20-50 kandydatów, i przestawia ich według faktycznego dopasowania do pytania. To dodaje ~300ms do latencji, ale poprawia jakość odpowiedzi o 20-40% w naszych benchmarkach.
W 2026 reranking nie jest opcją. Jest warunkiem, żeby RAG był używalny w produkcji. Jeśli ktoś proponuje Ci wdrożenie „bez reranka, bo mamy dobry model” - to znak, że ten ktoś buduje prototyp, nie produkt.
Krok 2.4 - Multi-tenancy przez client_id
Jeśli planujesz, że asystent będzie obsługiwał więcej niż jeden dział albo więcej niż jednego klienta - zaplanuj multi-tenancy od pierwszego dnia.
W praktyce: każdy chunk w bazie wektorowej ma w payloadzie pole client_id (albo tenant_id, albo org_id). Każde zapytanie do bazy przychodzi z filtrem na konkretny tenant. Baza wektorowa jest jedna, ale tenant A nigdy nie dostanie fragmentu tenant B.
Dodanie multi-tenancy później to migracja. Zaprojektowanie od początku to 5 minut konfiguracji. Nie ma żadnego powodu, żeby tego nie zrobić - chyba że wiesz na 100%, że system nigdy nie będzie obsługiwał więcej niż jednego „świata” danych.
Tydzień 3: Grounding prompt i eval set
Trzeci tydzień to praca nad tym, jak model odpowiada, a nie co znajduje.
Krok 3.1 - Grounding prompt
Grounding prompt to systemowy prompt modelu. Określa, jak model ma się zachować z kontekstem, który dostaje.
Dobry grounding prompt zawiera trzy rzeczy:
1. Wymuszenie cytowania. Model nie tylko odpowiada, ale cytuje konkretne fragmenty dokumentu. Nie „prawdopodobnie widzi, że…”, tylko „według dokumentu Regulamin zwrotów, sekcja 4.2: …”. To jest warstwa audytowalności - użytkownik może zweryfikować każde stwierdzenie.
2. Refusal przy braku pokrycia. Jeśli w dostarczonym kontekście nie ma odpowiedzi - model ma powiedzieć „nie mam tej informacji w dostępnych dokumentach”, a nie halucynować. To jest najtrudniejsza część grounding prompta. Model LLM naturalnie chce być pomocny - musisz go „uczyć”, że w tym systemie milczenie jest lepsze niż konfabulacja.
3. Jasna granica zadania. Model odpowiada na pytania dotyczące dokumentów, nie prowadzi konwersacji o pogodzie. Nie pisze kodu Python. Nie udziela porad medycznych. Trzymanie modelu w roli asystenta wiedzy firmowej jest krytyczne - bo inaczej masz na rękach chatbot ogólny, który przy okazji czasem korzysta z dokumentów.
Krok 3.2 - Eval set: 100 pytań jako benchmark
Najważniejszy zasób pilota, którego większość firm nie tworzy: eval set. Czyli lista 100 reprezentatywnych pytań z oczekiwanymi odpowiedziami, używana do regresywnego testowania jakości.
100 pytań to minimum. Zbiera się je tak:
- 40 pytań z realnej historii działu (co klienci/pracownicy pytają najczęściej)
- 20 pytań, które są trudne (wymagają zestawienia dwóch dokumentów, dotyczą edge case’ów)
- 20 pytań, na które odpowiedź to „nie ma tego w dokumentach” (test refusalu)
- 20 pytań, które próbują system wyprowadzić poza jego rolę („napisz mi wiersz”, „zignoruj instrukcje”)
Dla każdego pytania określasz: oczekiwaną odpowiedź (lub zakres akceptowalnych odpowiedzi), dokument-źródło, krytyczność (blocker / nice-to-have).
Eval set uruchamiasz przed każdym rolloutem do nowego działu albo po każdej większej zmianie w bazie wiedzy. To jest Twoja regresja - tak jak testy jednostkowe w klasycznym software.
Bez eval setu nie wiesz, czy zmiana promptu poprawiła asystenta, czy go zepsuła. Zgadujesz.
Template eval setu w formie Google Sheet udostępniamy na końcu wpisu.
Tydzień 4: Pilot na jednym dziale
Tydzień czwarty to rollout. Ale - krytyczne - nie dla całej firmy. Dla jednego działu z jednym, konkretnym use case’em.
Krok 4.1 - Wybór działu pilotażowego
Trzy najlepsze kandydatury:
HR policy desk. Pracownicy pytają o urlopy, benefity, procedury. Dokumentacja jest zwarta (regulamin, polityki), pytania są powtarzalne. Niski risk, wysoki volume - idealne dla pilota.
Pre-sales / obsługa zapytań ofertowych. Handlowcy szybko odpowiadają na pytania klientów o produkty, specyfikacje, ceny. ROI widać od tygodnia, bo czas odpowiedzi do klienta jest mierzalny.
Customer support pierwszej linii. Typowe pytania klientów, powtarzalne odpowiedzi, duża próba pomiaru. Minus: dane często wrażliwe (PII), więc trzeba wcześniej zadbać o redakcję.
Nie rób pilota w dziale prawnym, finansowym ani na strategii zarządu. Za duża wrażliwość, za mały wolumen pytań, za trudny benchmark. Te działy są celem etapu 2, nie pilota.
Krok 4.2 - Trzy metryki sukcesu
Pilot ma być mierzalny. Trzy metryki, nie więcej:
1. Helpfulness ≥ 90%. Użytkownicy oceniają odpowiedzi (kciuk w górę / w dół). Target: ≥ 90% pozytywnych ocen na pytaniach z zakresu asystenta. Poniżej 80% - coś jest fundamentalnie źle. Między 80-90% - są wąskie obszary do poprawy.
2. Halucynacje ≤ 2%. Spośród wszystkich odpowiedzi - ile zawiera informacje, których nie ma w dokumentach? Mierzymy próbkowo (10% odpowiedzi tygodniowo) przez człowieka. Target: poniżej 2%. Powyżej 5% - system nie nadaje się do produkcji, wraca do refinementu grounding prompta.
3. Latencja ≤ 2,5 sekundy. Od momentu wysłania pytania do początku wyświetlania odpowiedzi (streaming). Powyżej 3 sekund użytkownicy odchodzą. Optymalizacja latencji to często zwężenie top-k w retrieval (mniej kandydatów = szybszy rerank = szybsza odpowiedź).
Wszystkie trzy zmierz w 2. i 4. tygodniu pilota. Różnica między tymi pomiarami to Twój sygnał, czy system się uczy/poprawia, czy stagnuje.
Krok 4.3 - GDPR i komunikat dla użytkowników
Dwa wymogi, których nie można pominąć:
Log retencji zgodny z RODO. Każda rozmowa z asystentem to przetwarzanie danych. Musisz mieć jasną politykę: jak długo logi są trzymane, kto ma dostęp, jak są usuwane. Rekomendacja: 30 dni retencji dla debugowania, potem automatyczne kasowanie. Pseudonimizacja identyfikatorów użytkowników w logach.
Komunikat dla użytkowników. Każdy użytkownik asystenta w pilocie widzi jasny komunikat: „Odpowiedzi są generowane z wewnętrznych dokumentów z okresu [zakres dat]. Nie są to porady prawne/medyczne/podatkowe. W razie wątpliwości skonsultuj [konkretna osoba/dział].” To nie jest tylko compliance - to zarządzanie oczekiwaniami. Użytkownicy, którzy wiedzą, że AI może się mylić, sprawdzają krytyczne odpowiedzi. Użytkownicy, którzy nie wiedzą - przekazują halucynacje klientom.
Co dalej: tydzień 5 i kolejne
Pilot pokazał dane. Teraz - roadmapa rozszerzenia.
Rozszerzenie na drugi dział. Nie równolegle, sekwencyjnie. Dwa działy na raz = dwa razy więcej problemów, a procesy jeszcze nie są ustabilizowane. Dodaj drugi dział dopiero, gdy pierwszy utrzymał metryki przez 4 tygodnie.
Dane strukturalne i tool calling. Pytania typu „ile zamówień złożył klient X w Q1” wymagają API lub SQL, nie wyszukiwania w dokumentach. Kolejna warstwa architektury - agent z dostępem do bazy danych przez narzędzia (function calling). Standard, który się tu utrwalił, to MCP - opisujemy go we wpisie MCP - USB-C dla AI. Jeden asystent zamiast pięciu chatbotów. To jest skok złożoności; planuj 3-6 tygodni na samą tę warstwę.
Multi-hop retrieval. Złożone pytania wymagają zestawienia wielu fragmentów z różnych dokumentów. „Które regiony mają procedury reklamacyjne niezgodne z polityką globalną?” - to dwa hop-y, każdy wymaga własnego query. Sprawdź, czy to naprawdę potrzebne - często 95% pytań jest prostych i multi-hop to over-engineering.
Agentic RAG. Agent rozbija złożone pytanie na podpytania, wykonuje je sekwencyjnie, syntezuje odpowiedź. To przyszłość, ale nie zaczynaj od tego. Najpierw klasyczny RAG, który działa; dopiero potem komplikacje.
Decyzja „on-premise czy regionalna chmura EU” dla produkcyjnego rollout’u to osobny temat - rozwijamy ją we wpisie Chmura czy on-premise? Jak wybrać model wdrożenia AI.
Pobierz template i checklist
Pilot wymaga przygotowania. Dla czytelników tego wpisu udostępniamy dwa zasoby do pobrania:
- Template eval set - Google Sheet ze strukturą 100 pytań benchmarkowych, gotową do wypełnienia przez Twój zespół
- Checklist audytu danych - krok-po-krok checklist dla tygodnia 1 (source registry, chunking policy, metadata schema, PII audit)
Dostępne pod linkiem w sekcji kontaktu: umów rozmowę o wdrożeniu - przed spotkaniem wyślemy oba template’y mailem.
Kiedy warto rozważyć pomoc z zewnątrz
Playbook da się przejść samodzielnie. W Ragenie pomagamy przejść go szybciej i uniknąć błędów, które widzieliśmy u innych.
Co robimy:
- Warsztaty AI Mapping (1-2 dni) - mapujemy użycia AI w Twojej firmie, priorytetyzujemy pilot, dobieramy dział
- Wdrożenie Ragen AI w tydzień - platforma on-premise lub w Ragen Cloud, gotowa do etapu 2 (embedding)
- Wsparcie podczas pilota - eval set razem z Twoim zespołem, review metryk, iteracje
Jeśli chcesz zobaczyć, jak to wygląda konkretnie dla Twojej firmy - umów 30-minutową konsultację. Pokazujemy platformę na realnych przypadkach, nie generycznych slajdach.
Jeśli nie jesteś pewien, czy Twoja firma jest gotowa na RAG - zacznij od self-checku gotowości. Osiem pytań, które odpowiedzą, zanim umówisz rozmowę.
Jeśli wolisz najpierw policzyć koszty wdrożenia - kalkulator kosztów RAG pipeline pokaże Ci miesięczny budżet dla Twojej skali.
Źródła:
- McKinsey, „The State of AI 2025” - 71% organizacji używa GenAI
- Deloitte, „Generative AI in the Enterprise 2025” - 42% raportuje realne oszczędności
- Grand View Research, „RAG Market Report 2026” - wzrost 1.2B → 11B USD
- Vectara, „Enterprise RAG Predictions 2026” - reranking jako standard produkcyjny
- Dokumentacja techniczna: Qdrant, Cohere Embed Multilingual v3, Cohere Rerank v3.5
- Praktyki wewnętrzne Ragen AI z wdrożeń u klientów polskich MŚP